|
Latent Rank Theory (Neural
Test Theory) |
||||||||||||||||||
|
This
website introduces the latent rank theory (LRT) / neural test theory (NTT),
which is being developed by Kojiro Shojima and his colleagues. LRT is a
nonparametric test theory that uses a mechanism based on the self-organizing
map (SOM) or generative topographic map (GTM). Quick Introduction PPT Example of Can-Do Chart PDF |
||||||||||||||||||
|
LRT
(NTT) was first presented at the International Meeting of the Psychometric
Society in 2007 (IMPS2007) in Tokyo, and many foreign and domestic
researchers and test practitioners have expressed interest in it. |
||||||||||||||||||
|
Conventional
Test Scoring on a Continuous Scale |
||||||||||||||||||
|
The academic achievements of students
in classrooms around the world are evaluated on the basis of test results
expressed on a continuous scale. However, is there a substantial difference
in the achievements of two students if one receives, for example, 65 on a
0—100 scale and the other receives 70. It would probably be difficult
to distinguish the difference because it is likely to fall within the margin
of error. Can we rely on scores on a continuous scale as a measure for
evaluating academic achievements or in selecting applicants taking an
entrance exam? |
||||||||||||||||||
|
Tests simply don’t have
sufficient resolution (i.e., “reliability”) for distinguishing the
difference between two people with nearly equal abilities. A weighing
machine, for example can used to detect even slight differences in weight
between two people, but it is practically impossible for a test to
distinguish a slight difference in abilities. The reliability of an ordinary
weighing machine is sufficient for us to readily believe that Student A is 2
kg heavier than Student B if the machine says that Student A weights 62 kg
and Student B weighs 60 kg. However, we would likely doubt that the ability of
Student C is certainly slightly higher than that of Student D if Student C
scores a 62 on a test and Student D scores a 60. The most that tests
can do is to rank the test takers into 5—20 levels. In fact, some
teachers assert that it is practical to rank them into only five levels
Excellent, Very Good, Good, Below Average, and Needs Improvements. |
||||||||||||||||||
|
Although some people argue that
expressing scores on a continuous scale is effective from the viewpoint of
motivation because the scores generally differ a bit each time a test is
taken, an effort should be made to prevent students from swinging between
feeling happy and sad in response to such differences because human abilities
cannot be drastically changed overnight. While “continuous scoring”
is very convenient for precisely matching the number of entrance exam passers
to the number of admission slots. However, graded evaluation can reduce the
excessively authoritative status of testing, which would encourage the use of
factors other than test scores such as school records and interviews. |
||||||||||||||||||
|
Test Standardization Theory
for Grading Academic Achievement |
||||||||||||||||||
|
How can we grade academic achievement? Graded
evaluation of academic achievement is inseparably connected to constructing a
qualifying test, the result of which can be used to construct an
“ability catalog” for each examinee and to certify the level of
the test taker’s mastery of each item in the catalog. |
||||||||||||||||||
|
Before such a qualifying test for grading
academic achievement can be created, a suitable test theory must be
developed. Test theories are statistical theories for standardizing tests and
administrating them over the years. Item response theory (IRT) is the
prevailing test theory, and many large-scale tests such as TOEFL, TOEIC, and
NAEP are administered in accordance with IRT. However, since IRT is based on
a continuous ability scale and locates examinees’ abilities on that
scale (e.g., the paper-based version of TOEFL has a continuous scale ranging
from 300 to 677), the IRT is not a satisfactory test theory for standardizing
tests to become qualifying tests. A test standardization theory in which
examinees’ abilities are evaluated on not a continuous scale but an
ordinal scale is necessary for ability grading. Of course, the
continuous scale of IRT can be used for graded evaluation by dividing it at
several points though where to locate the points would be problematic. |
||||||||||||||||||
|
We are developing a latent rank theory
(LRT) / neural test theory (NTT) that will be satisfactory for standardizing
tests to become qualifying tests. LRT/NTT is a
statistical model comprising the self-organizing map (SOM) or generative
topographic map (GTM) mechanism and is a test theory for grading academic
achievement on an ordinal measurement scale. |
||||||||||||||||||
|
Test Theory
for Administering Qualifying Tests |
||||||||||||||||||
|
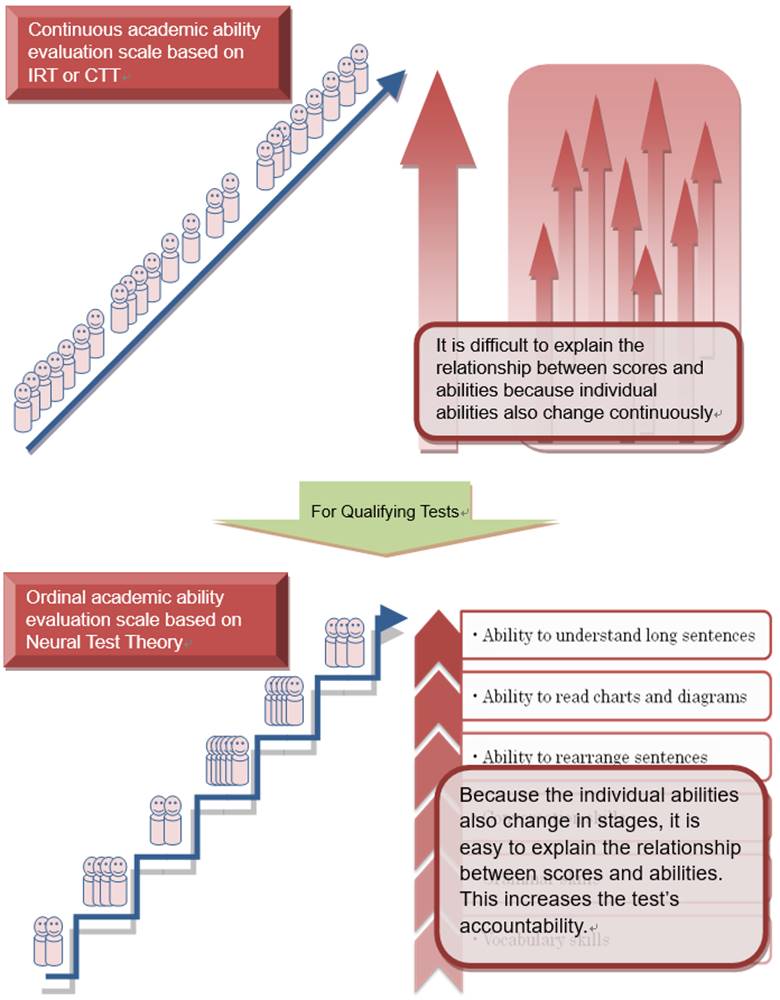
The figure illustrates the difference
between the traditional continuous ability scale and the LRT ordinal scale
for graded evaluation. Every test should have a function for not only
selecting passers but also for diagnosing each examinee’s abilities.
Therefore, it is particularly important that a test can be used to construct
an ability profile for each achievement level (latent rank) and to
construct an achievement progress table (can-do chart; see
Accessories). It is much easier to make a can-do chart using an ordinal
ability scale than a continuous one because describing the can-do statements
corresponding to each achievement level is only practical when the ability
scale is ordinal. Drawing a can-do chart is equal to controlling the
quality of the test. The chart secures accountability of the test by
manifesting what the test measures, so only the chart can hallmark the test.
|
||||||||||||||||||
|
Latent Rank Theory |
||||||||||||||||||
|
Neural test theory is a statistical
model in which the latent variable is ordinal. Such statistical theory has
not been established. Therefore, we propose a framework called “latent
rank theory (LRT)”.
The NTT is a latent rank theory that
uses the self-organizing map (SOM) or generative topographic map (GTM) mechanism
to estimate the NTT model. The model with the GTM mechanism (LRT-GTM) is a
batch-type learning model, and computation time for estimation is much faster
than that of the model with the SOM mechanism (LRT-SOM). In addition, the
calculation results are invariant with the LRT-GTM model, while they vary
slightly with the LRT-SOM model, although the fluctuations are negligible.
However, the item reference profile (see Feature) obtained with the LRT-SOM
model is a little smoother than that with the LRT-GTM model. |
||||||||||||||||||